
Minding the Data Quality Gap
The AI training data market is behaving like an early commodity market. We need to rethink data QA processes and metrics from the ground up to unlock the market efficiency that feeds AGI.



Before the Chicago Board of Trade introduced standard grades for wheat in 1857, every farmer’s crop was dumped into the same grain elevators, mixing good grain with diseased grain and dirt. For centuries of local trade, this hadn’t been a big problem. But when railroads and industrial-scale production increased wheat volume exponentially, the old mechanisms of trust and verification could not keep up. Notably, this benefited the old incumbents.
The rapidly evolving market of AI training data, the “new age commodity,” has a similar feel. Firms like Scale, Surge, and Mercor generate eye-watering revenues from labeling data and sourcing experts for AI lab hyperspenders. Whether what they’re selling is truly destined to be a commodity, and how the dynamics will evolve, is less clear. What is clear is that the quality bottleneck is slowing everyone down. Learning the history of commodity markets during my time at a global macro hedge fund led me to see familiar patterns.
When something suddenly becomes valuable, the first phase of market formation is defined by opaque, bilateral deals for the physical good and immediate delivery, aka the spot market. The market is small, inefficient, and fragmented. Because there are no standards, every buyer must physically inspect the goods to ensure quality, e.g., checking that the wheat isn’t moldy or the gold is pure. The first generation of brokers emerges somewhere in the middle of this mess. As volume grows, trust and inspection become constraints.
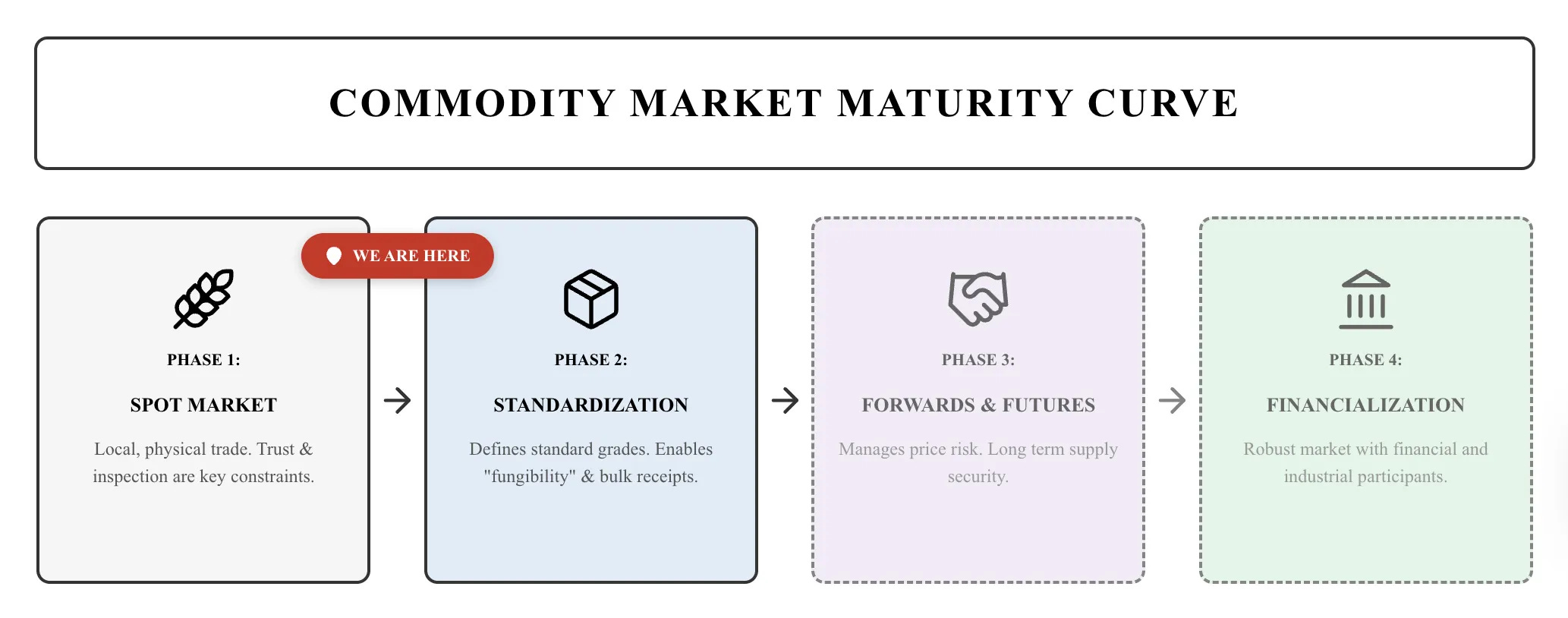
The market wants to scale further, and liquidity can be unlocked by developing higher-quality measures and standardizing product grades.
The State of Data Quality Control
Assessing training data quality today is slow, labor-intensive, unreliable, and haunted by bad incentives. Despite the industry producing ever-increasing volumes and variety of data, brute-force manual audits remain the predominant QA practice. Human reviewers certify thousands of samples one at a time, and the process is repeated twice because the seller and buyer don’t trust each other to catch all the issues. Each round of data spec, production, seller QA, delivery, buyer QA, and feedback can take months to complete.
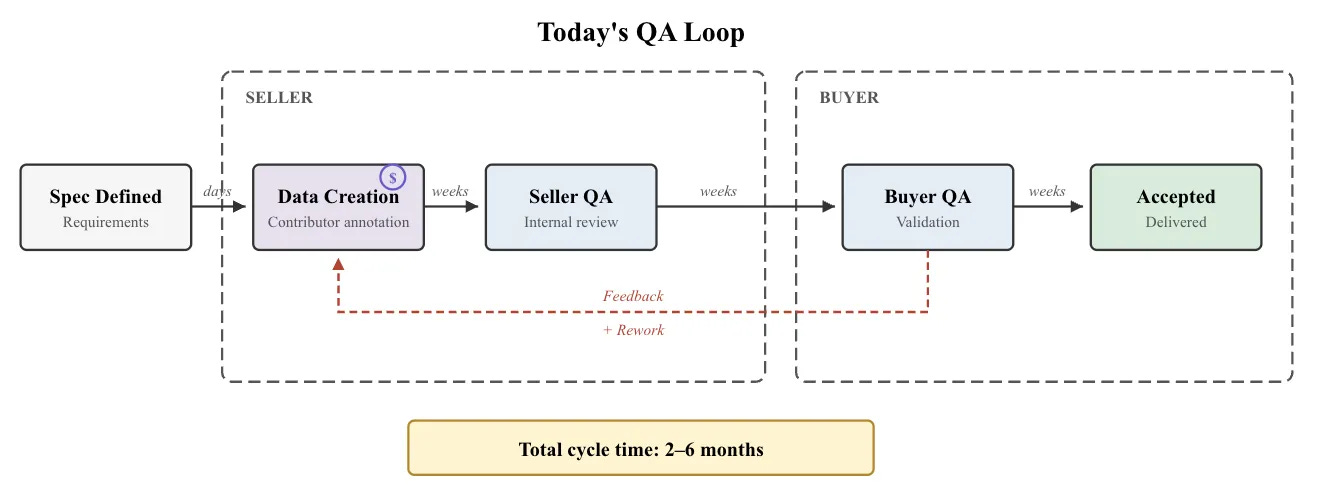
Since full audits are prohibitively expensive, market participants resort to weaker proxies. Spot checks are reasonable, but applied inconsistently. Contributor credentials and assessments offer upfront competence checks, but credentials are hard to verify and easy to exaggerate, and neither approach enforces behavior once work begins. Inter-rater agreement works from the other direction, catching issues after the fact, but disagreement could reflect poor output, ambiguous instructions, or genuine expert differences. None of these methods is wholly unreasonable, but none is particularly robust either.
The other day, I listened to an interview with the founder of a prominent training data company, who discussed sourcing the world’s best poets to improve AI’s performance in writing poetry. It was amusing to contemplate a very SF-coded worldview, in which the next W.B. Yeats or Sylvia Plath could be found doing gig work for $150/hour, taking online tests to prove they understand what poetry is, and spending their evenings rating other poets’ work on a 1-10 scale.
This is all made worse by bad incentives that turn the quality problem adversarial. The competing labs, brokers, and contributors are playing a secretive game of telephone between specs and outputs. Contributors are paid per task, the tasks are getting more complex, quality is getting harder to evaluate, while quantity remains easiest to count. The same data annotators have been found using multiple accounts and VPNs to appear as multiple people working for multiple subcontractors. Rational actors take shortcuts on the supply side to pump out more product when weak metrics are easy to game.
The Symptoms
To gauge just how rudimentary data QA is today, look no further than the flagship datasets and benchmarks we rely on in AI development.
SWE-Bench is the de facto standard for measuring AI competence on software engineering tasks. For the initial release, Princeton researchers shipped a dataset of 2,294 tasks scraped from GitHub and validated entirely by an automated pipeline, citing the overhead of human QA as a barrier to keeping the benchmark continuously updated. Subsequently, due to data quality issues, OpenAI had to hire 93 software engineers to re-evaluate 1,699 samples from the original SWE-Bench, and SWE-Bench Verified was born. Each sample was reviewed by 3 separate contributors, and 78% of the original data was discarded due to various issues. A later study, SWE-bench+, found that the “fixed” benchmark needed its own fixes, and that 60% of the tasks in Verified had solution leakage. The solutions were provided or hinted at in the task prompt. Finally, a new class of problems emerges when the environment is interactive - in September 2025, a researcher discovered a bug in the official evaluation environment where an agent could look up the solution by inspecting the “future” commit history via a clever combination of git commands.
Another blue-chip benchmark, MMLU, designed to evaluate performance on 57 complex subjects, was found to have a 6.5% defect rate by independent researchers. That doesn’t sound too bad? Except that it turns out some individual categories had a massive defect rate. Virology contained up to 57% invalid examples, and Chemistry had a 20% error rate.
These are scoped, high-stakes, heavily audited benchmarks built by well-resourced teams with PhD experts and months of curation. If we can’t stop playing whack-a-mole with the problems hiding there, the current QA approaches may well be dead in the water.
The RL Discontinuity
Even if the legacy metrics and methods at least kind of work on static datasets, they break down completely with the market shift towards reinforcement learning environments for post-training.
Despite the ongoing gold rush, there’s little grounded wisdom for what exactly distinguishes a good RL environment from a bad one. The combinatorial explosion alone makes spot-checking long trajectories impractical. You can’t manually check your way through a state space that branches with every action over hundreds of steps, with all the possible reward values. Quality isn’t contained in any one part of the environment; it emerges from the interaction of task design, action interface, state space, and reward shaping.
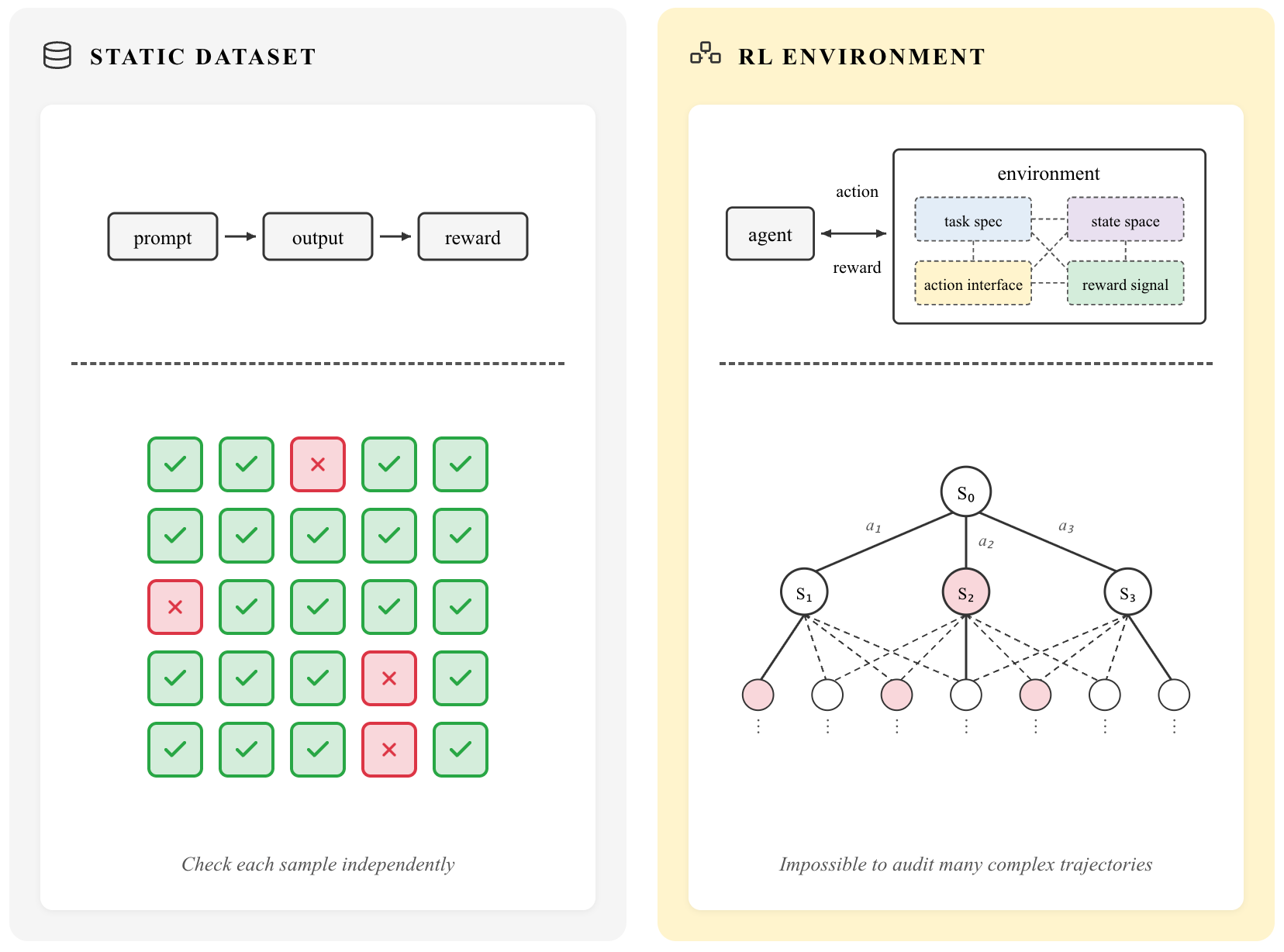
Should a sales AI agent train on a production-grade CRM directly, or is it better to strip down the functionality? Should the interface be computer use, a raw REST API, or a custom-specified set of tools? Should the database be populated with clean fake data or messy production exports? These decisions lie on spectrums with no established best practices, and a target domain expertise alone is not enough to get it right. A great software engineer can label code quality, but that doesn’t mean they can design an environment where the right behaviors emerge under optimization.
Traditional QA also assumes you’re filtering out bad examples, but RL environments need failure modes and adversarial states to teach robustness. The goal is the right level of difficulty, and we don’t yet know how to verify it.
This is all before considering the impending future of multimodal RL, where agents train across fielding voice calls, analyzing visual charts, writing text, and executing code, all in the same trajectory. The idea of manual quality control becomes completely untenable.
The only definitive test of an RL environment’s quality is whether training in it produces good downstream behavior. This calls for rethinking data quality measurement from the ground up.
New Measures
Establishing data quality standards requires metrics that can be applied rigorously across diverse data streams. An ideal metric should satisfy three properties suggested by the failures and challenges above:
Predict downstream model generalization
Be task-agnostic and comparable across heterogeneous data types
Be computable without exhaustive manual review
A recent paper by Finzi et al. proposes a promising candidate that meets these criteria: epiplexity (epistemic complexity). Epiplexity measures how much structural, learnable information a computationally bounded observer (e.g. a neural network) can extract from a dataset.
Concretely, the metric is estimated as the area under a model’s training loss curve above its final loss. Intuitively, this area captures how much structure the model must progressively internalize during training.
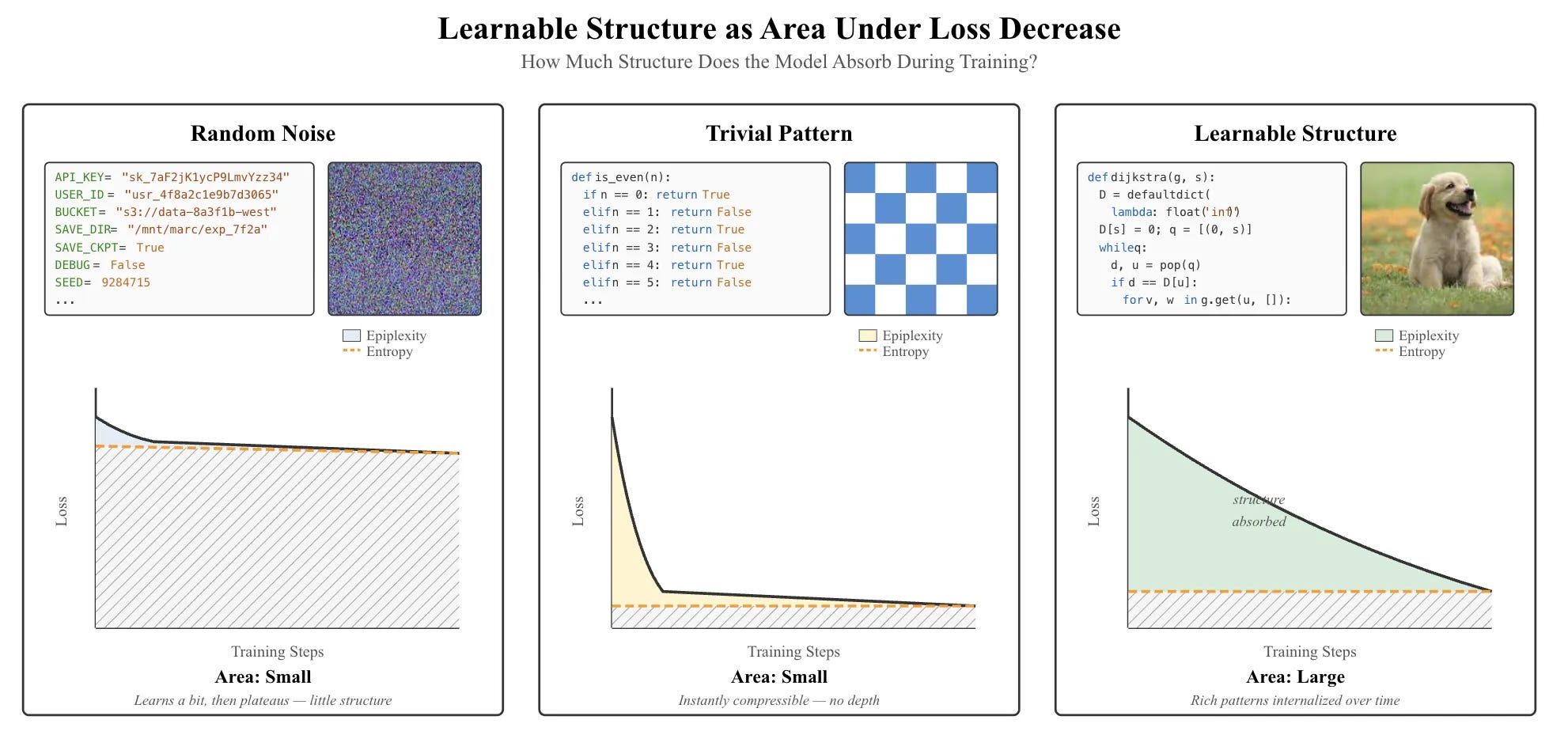
To see why this matters, consider 3 cases:
First, consider training on random noise—say, a configuration file full of API keys. Because there is no underlying structure to learn, the loss barely decreases. The resulting area is small.
Second, consider trivially repetitive data, such as the sequence “0101010101…”. Here, the loss collapses almost immediately once the pattern is recognized. Again, the area is small.
By contrast, when a model trains on data with rich, compositional structure, such as the source code for Dijkstra’s algorithm, the loss decreases gradually over time. The model must internalize abstractions around graphs, priority queues, and shortest paths. This sustained decrease corresponds to structure being absorbed into the weights, producing a large epiplexity value.
With this intuition in place, the empirical results map cleanly onto the desired properties above.
To show that epiplexity predicts generalization, the authors train models on identical chess datasets presented in two different orderings: one showing moves before the final board state, and one reversing this order. The reversed ordering is more challenging to learn, exhibits higher epiplexity, and produces models that significantly outperform on downstream tasks requiring board-state understanding.
To demonstrate comparability, the metric is applied across natural language (OpenWebText), chess games (Lichess), and images (CIFAR-5M). Language data exhibits the highest structural information per token, providing a framework for why text pretraining transfers broadly, while image pretraining tends to be more domain-specific.
Finally, epiplexity is computationally practical. Estimation requires only a small model trained under a fixed architecture and protocol. The authors’ experiments use models up to 160M parameters, making evaluation feasible on a single GPU.
Whether or not epiplexity becomes the industry standard, the paper is a blueprint for quality metrics that are theoretically grounded and broadly applicable. Let’s return to data procurement. Using a metric like epiplexity, two vendors offering “one million expert demonstrations” could, in principle, be compared apples-to-apples with a modest compute investment. As the datasets bought and sold today continue to diversify, metrics like this offer a path toward shared intuitions for evaluating investments in pretraining corpora, SFT input–output pairs, preference rankings, expert rubrics, and reinforcement learning environments.
Implications
Back in the 19th-century US, the breakthroughs in wheat grading led to a dramatic expansion in the scale and efficiency of grain markets. Chicago became the dominant hub for American grain trading, prices became more transparent and consistent across regions, and the model was eventually replicated worldwide for other commodities.
The parallel for AI training data is suggestive if not exact. Wheat is fungible in a way that data never fully will be, because the AI frontier is a moving target. But right now, the bottleneck to progress is the slow, adversarial, unreliable process of turning human knowledge into a learning signal. The closer we get to measurable quality and standards, the faster capital and compute will flow toward what works. A more efficient and transparent training data market is one where smaller vendors can compete on quality rather than pure scale, and negotiations and QA cycles are shortened by shared baselines.
The question is who drives standardization. Historically, it has rarely been the largest buyers or sellers, as both benefit from information asymmetry and have little incentive to give it up. The labs treat evaluation methods as a competitive advantage, and revealing how they validate the best data would expose their research agenda. Data producers want to present their product as bespoke, and standardized metrics would make them directly comparable, compressing margins. A neutral third party whose business depends entirely on measurement credibility may be better positioned to build trust on both sides.
Every shift in training paradigm will create another quality measurement gap to close. Whoever builds the infrastructure to close these gaps systematically will help determine how fast we can move from here to AGI.
 | A guest post by
|