
Rewards Are Everywhere
General purpose co-working agents are still awaiting their Claude Code moment. Musings on mining Reward Signals for training General Agents.



When will we have Claude Code for everything else?
Every now and then there is a product release so compelling that it escapes the confines of our tech bubble to capture the imagination of even the most passive of observers. Claude Cowork was one of them. Code agents have enjoyed the limelight for providing exponential leverage to software engineers. The creator of Claude Code notes that 100% of Claude Code is now written by Claude Code.
The race is on to unlock code copilot performance for every computer task. The anxieties around the marginal cost of knowledge work going to zero are warranted, but the magic moment still has not happened for most users. The experience still feels half-baked, requiring laborious user intervention. The frontier is evident. How do we replicate coding efficacy for medicine, finance, design and other everyday tasks?
Fundamentally, this is a data problem. “Verifiable Domains” like math and code are hillclimbing rapidly, allowing models to develop reasoning from binary correctness signals alone. Knowledge workflows that are considered to be “subjective” or “taste based” are still stuck on “what does good look like.” This evaluation bottleneck for AI agents is real, but misdiagnosed. “Expert Domains” already contain a treasure trove of verifiable end states that provide direct signal for both evaluation and training.
A metric for the magic moment
In the agentic era, the challenge is not creating a single output, but a trajectory. An agent should plan and execute a sequence of actions to autonomously achieve a goal. A core metric for the improvement in AI capabilities is measuring the ability to complete long tasks. METR measures this by comparing how long tasks take humans against the AI’s likelihood of completing them at different success thresholds (50%, 80%, 100%). The Magic a user feels is proportional to the Task Complexity possible with the minimum user input Interaction Cost. This is why Claude Code feels like having John Carmack himself living in your terminal, and general Coworking Agents feel like managing an overenthusiastic summer intern.
Verifiable domains are hillclimbing rapidly
It makes sense that math and code would see the steepest advancement in capabilities. Quantitative domains are the most objectively verifiable. A math problem has a right answer. The code either compiles or it doesn’t.
Empirically, Reward is enough. Place an agent in a sufficiently complex environment with only clear reward signals and sophisticated abilities will emerge. It took some time to converge on a training paradigm for LLMs that allowed us to leverage this heuristic. Finally, with the architectural unlock of R1, chain-of-thought reasoning emerged. Along with a bit of cold-start supervision to stabilize training, the core learning signal required only a correct final-answer. Through the newly minted Group Relative Policy Optimization (GRPO), we have finally unlocked classical reward seeking for agent training.
As a result, code agents have longer horizons than ever. Looping through console errors and self-generated tests, Claude Code can tirelessly work through a single task for more than 30 hours straight. The neologism “one-shotted” is apt as the model can resolve tickets or build entire apps from a singular prompt.
Math models are at the precipice of human ability. Consider the prestigious International Math Olympiad (IMO), which counts 11 Fields Medalists (including Terence Tao, Maryam Mirzakhani, and Grigori Perelman) as former winners. In 2024, AlphaProof achieved IMO Silver by training on formally verified Lean proofs. In 2025, Gemini Deep Think re-architected its approach, simply training on curated problem + solution pairs. The AI achieved a Gold Medal by increasing the number of self-verified turns it was able to take in the two allotted 4.5 hour sessions. The chase is now on to address Navier-Stokes and the Erdos problems.
This is why standing on the peaks of the jagged frontier makes the valleys seem so distant.
Replicating the success in expert domains
The question then becomes, how do we hillclimb the remaining expert domains as effectively? The challenge is procuring data, formatted as “verifiably correct examples,” to feed the cutting-edge training algorithms. For instance, PPO and DPO are designed for pairwise preferences, while GRPO excels on rubrics. Unfortunately, the prevailing production process requires expensive experts to hand-craft reward signals. In order to chef better training paradigms, we first need to understand what we are feeding models today.
Rubrics.
Rubric evaluation decomposes the signal into weighted dimensions, converting sparse binary outcomes into dense rewards. Where pass/fail evaluation yields a single signal per task, rubrics provide a vector of partial credits that enable finer-grained (Partial Rewards, Negative Rewards, Stepwise) credit assignment. This is requisite for subjective domains, where a math proof has a singular objective, experts have multiple criteria to drive a successful outcome (accurate diagnosis + treatment plan + consider side effects). Overfitting to one signal risks reward hacking.
Recent work such as HealthBench and PRBench have applied rubrics to medicine, finance, and law.
Limitations
The advancing frontier depends on experts to manually label datum. For reference, GPQA paid PhD specialists $100 per hour, 2 hours per question, to produce just 448 questions covering biology, physics, and chemistry. Additionally, this process is slow; just one benchmark, ResearchRubrics, required over 2,800 hours of human labor to create.
Preferences.
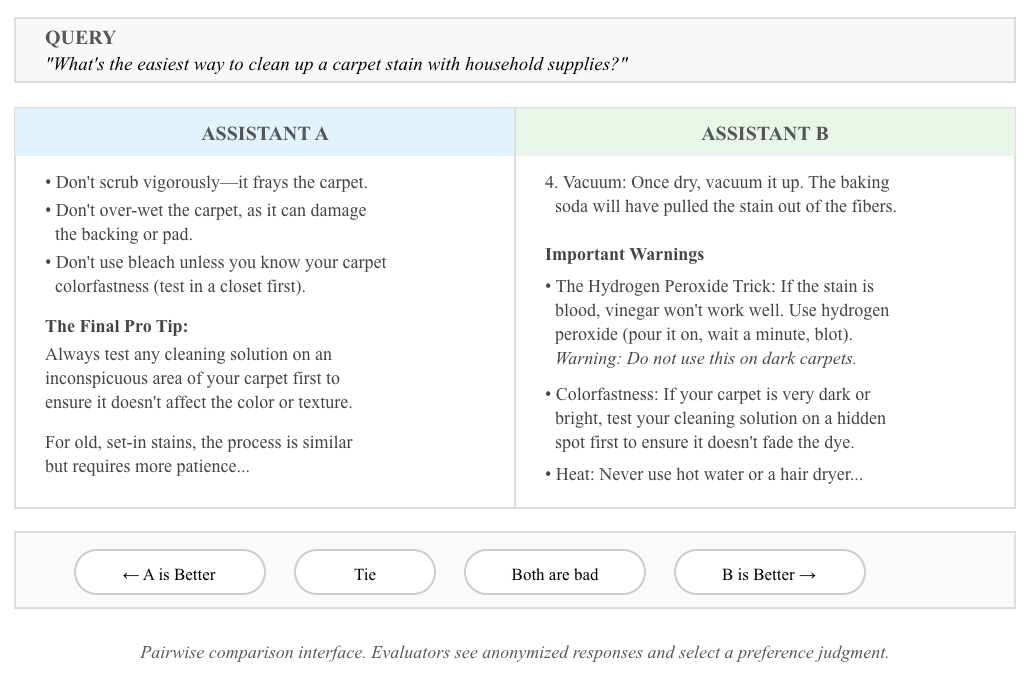
Preferences take two outputs and ask a judge to determine which is superior. Win rate is ideal for quickly specifying valuable tasks without being required to specify the ideal outcome. This is well utilized for “subjective” tasks like design or producing documents.
Recent work, such as GDPVal and Remote Work Bench test AI against an expert for a Human-AI win rate. Arena based evaluation pit outputs from different models against each other for an AI-AI win rate.
Limitations
Research shows that improvements on Arena actually worsened overall benchmark performance on MMLU. The Leaderboard Illusion demonstrates that optimizing for human-AI win rates hurts performance capability due to overfitting to subjective preference. For example, in the GDPVal assessment, Anthropic’s models consistently won out despite being slightly worse in objective correctness but significantly better at visual formatting, revealing the weakness of human judgement.
Scraping.
In order to most closely mirror real world demands, tasks + deliverables are scraped from public repositories (think GitHub, Fiverr, Upwork). The secondary benefit is that there is a measurable economic value to the task being completed.
Benchmarks like Remote Work Bench and SWE Lancer are compiled from scrapes of real-world job postings. SWE Bench is compiled from approved pull requests in open source repositories.
Limitations
The drawback is that these tasks are messy. The cleaning process for SWE Bench began with scraping more than 90,000 pull requests across more than 5,000 popular libraries. From there, only 12 repositories met the cleanliness bar to ultimately yield 2,294 tasks instances. Upon further inspection, this dataset was still too noisy and sifted into 500 “non-problematic” tasks to create SWE Bench Verified, netting a measly .55% yield rate.
The downside of these approaches is that they require costly manual effort to construct, don’t scale, and optimize for subjective preference. Despite the hundreds of millions of dollars poured in, progress in these domains continues to lag behind. This is now the tightest bottleneck to progress.
Real World Environments contain excellent reward signals
In the early days of the petroleum industry, kerosene was prized as lighting fuel for lamps. Gasoline was considered a volatile byproduct that refiners dumped into rivers or burned off as waste. With the invention of the internal combustion engine, gasoline became one of the most valuable commodities on Earth.
We have been synthesizing, when we should be prospecting. Right now the most valuable data on earth is treated as a byproduct of natural business operations. Real world professional workflows have always been structured around verifiable outcomes. The challenge is not to painstakingly construct reward signals but to identify those already embedded in operational infrastructure. If data is the new oil, this is how we go fracking for the most valuable crude.
Consider customer support… Every ticket is a trajectory. A customer raises an issue, the agent investigates, takes actions, and resolves. The intermediate steps produce artifacts (refund issued, database lookup, escalation message). The reward signal is also not singular but triangulated (Ticket marked resolved + Customer Satisfaction + Ticket reopen rate + Human intervention required). If any single signal is gameable, combined, they certify correctness. A discrete task is completed and the agent moves on to the next one.
The goal is training agents to autonomously execute long-horizon general tasks, without constant user input. In order to create the premier training signal we only need realistic tasks, a stocked environment to act within, and a record of the End State at successful completion. These rewards abound in virtually every domain. For example:
For Model Builders
For those building foundation models, getting close to ground truth rewards in real world environments will speed up training cycles and yield better outcomes.
The Reinforcement Learning environment should mirror the Real World
In training, an AI agent learns an internal representation of the environment in which it acts. Poor environment design creates a “sim-to-real gap.” The scattered strategy of buying hundreds of rough facsimiles (pared down mockups of Doordash, Linear, Netsuite etc.) could actually hinder learning. Over the years business software has co-evolved with operations to become a digital representation of the real world. The ideal implementation of the fabled “Reinforcement Learning Environment” is just one complex SaaS environment (an ERP, EHR, CRM). The goal should be to source diverse reward signals within a highly representative environment, not source hundreds of environments.
The trajectory needs to be unified from across sources
The request, granular decisions, and verification of a successful outcome may not all live in the same place. Identifying these touchpoints and establishing linkages creates the full picture. The richest training signal comes from workflows where all systems are digitized, with further excavation required if parts of the workflow live offline.
Long horizon tasks require a multitude of touchpoints
End-to-end business tasks require many touchpoints (i.e voice call + database query + pdf parsing + permissions change + email confirmation). Some of these may be public information, many of these will be internal applications and knowledge bases. Agents need to be natively trained for tool use and multimodality. Current training paradigms are fragmented to one or a few turns, overfitting training on a subtask to subtask level. When these learnings are duct-taped back together into a comprehensive model, any individual chokepoint will create a cascading failure. The most valuable workflows are greater than the sum of their parts.
The work is in refining raw data into training signals
Just as crude is refined into oil, high-quality training data has a production process. In order to avoid the issues that plague scraped datasets, the data infrastructure should be designed to facilitate training data creation. Most critically, the data needs to be formatted to be digestible by the training algorithms.
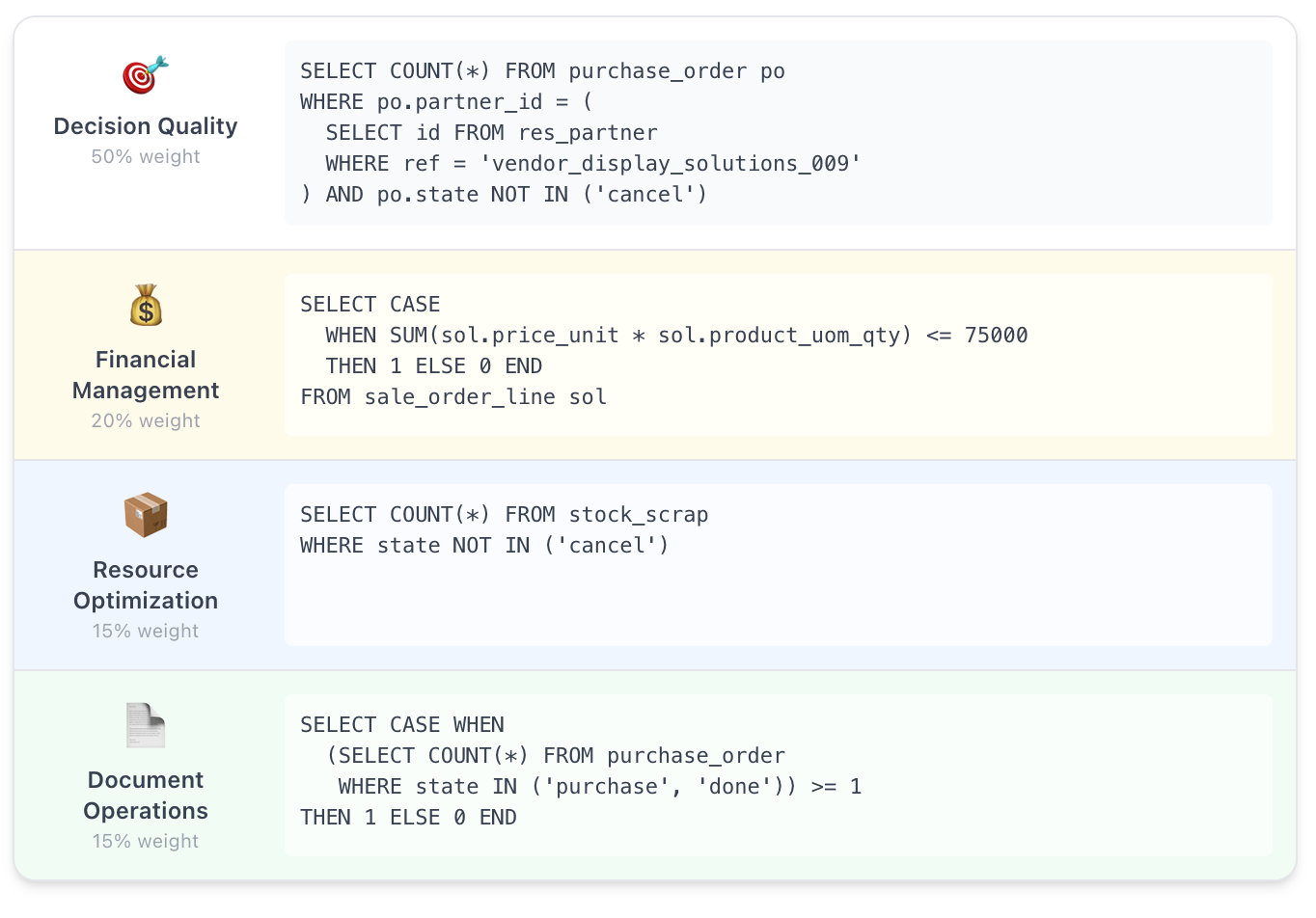
Back-office business processes can be transformed into rubrics of SQL queries. Golden documents can be used for pairwise preferences. Turning these dumps into training signals is precisely where talented data annotation workforces should be deployed.
For Enterprises
Enterprises are data producers and intelligence consumers, and labs are data consumers and intelligence producers. The relationship should be mutually beneficial.
Give the labs data, get better agents
Enterprises stand to benefit twice from data sales - first from the cash value of the transaction, and second from ensuring the AI is trained to their platform. In order to be a win-win, partnerships do not need to be limited to one-off fees for data dumps. Working to add more robust logs, understanding new task types, and providing updated data from new releases can create compounding symbiosis. An enterprise can sell a discounted present value of future dataflows. In empowering labs to improve their models to fit popular software environments (SAP, Salesforce, Epic), these providers will further entrench from receiving agents optimized to their products. The gusher to chase is creating continuous streams of data from the tasks and outcomes of a live business.
Look inward for finetuning
The implication is that enterprises that own this data not only can, but definitely should, build customizations leveraging their advantage. When considering a custom implementation or finetune, the data is already in the workflow. This strikes at the need of Reinforcement Learning as a Service. The challenge isn’t in finagling with complex post-training algorithms. Simply organize existing data into training and eval sets. For the Low Rank Adaptation Training, Tinker by Thinking Machines is only an API call away.
Data privacy is a concern, but not a blocker
The challenge with real data is that it comes from real users. While the data is stored in systems of record, it may “belong to” or be governed by consumer protections. GDPR, HIPAA, SOC2, etc. mandate compliance standards on how data is used. This is a hurdle that can be cleared; the data just needs to be de-identified. This can either be redacted or synthetically fuzzed. In healthcare, de-individuating patient data has been pioneered by Datavant, while tools like OpenMed highlight Personal Identifying Information (PII) through Name Entity Recognition (NER). This necessary precaution is not unique to extracted data. Additionally, it provides the opportunity to synthetically create a breadth of training points from each individual reference. The crucial reminder is that the structure of the workspace, tools being used, and sequence of decisions are most important for AI training - not the sensitive customer information itself. For safety, ensure that end users or customers opt to share their data for training purposes.

For Startups
Startups entering the arena should identify and invest in building a compounding data advantage.
AI startups should focus on sourcing preference labels from user interactions and specializing in out-of-distribution modalities.
The most successful “Application Layer” products are designed around these data flywheels.
Cursor has used completion acceptance to build a next action prediction engine and second finetune their own open source model.
Ramp has built its own AI native spreadsheet. The prompts, edits, and formulas from users provide a signal for improving the quality of AI-generated financial models.
Not everything reduces neatly to text. The defensible advantage comes from mastering less common data formats.
Reducto is scaling rapidly by parsing graphs and images with a much higher accuracy than traditional Optical Character Recognition. The insight that upwards of 80% of business data is stored in unstructured formats is a golden wedge.
Nomic is winning out by focusing on detailed structural diagrams, blueprints, and schematics. This under-appreciated niche accounts for petabyte scale datasets and undergirds billions in transactions.
David AI is dominating the sweltering hot modality of voice. Speech is used for the highest marginal value interfacing, like customer support, patient intake, or sales.
Parting Thoughts
The prevailing paradigm has it backwards. Labs are paying experts to hand-craft rewards while the most valuable signals flow through operational infrastructure every day - treated as a byproduct instead of the product. The verification is already happening. The path to coworking agents that actually work is not better rubrics or more human labels. It is recognizing that expert domains are more verifiable than we thought. The rewards are already there. Let’s go get them.
 | A guest post by
|
the training data market of today is in a strange superposition where the samples of real tasks done by real people are everywhere and nowhere at the same time
on the one side, the likes of surge and mercor are raising and earning billions by hiring experts to do pretend work at a premium, while existing companies are generating data from their workflows organically for ~free
this might be the arb of the decade
Nice article